Voxceleron2 Engine Architecture
Overview
Voxceleron2 is a voxel rendering engine I built to to try to have infinite worlds with very high render distances. The engine's end goal is to try to be as performant as possibler such that Signed Distance Fields can be used to represent changes to the world at runtime giving way to really nice fluid simulations and terrain deformation from things like explosions and weathering from rain.
The engine is built on Vulkan and uses a hybrid Sparse LOD Octree architecture to manage voxel data. Instead of storing everything at full resolution, chunks dynamically adjust their detail level based on distance from the camera. The rendering uses a fully deferred pipeline with SSAO and Bloom for visual polish. The core design focuses on data locality and asynchronous processing. Traditional pointer-based octrees suffer from cache incoherency because you're constantly chasing pointers through memory. My approach uses flat chunk arrays that scale in resolution based on distance, giving you the memory benefits of an octree with the access speed of a flat array.
The engine currently runs on my pretty humble hardware at a reasonable ~300FPS to 75FPS (and relative heavy load, see below), I use an Nvidia MX130, Intel i5-102110U @ 1.6GHz, 16Gb of RAM.
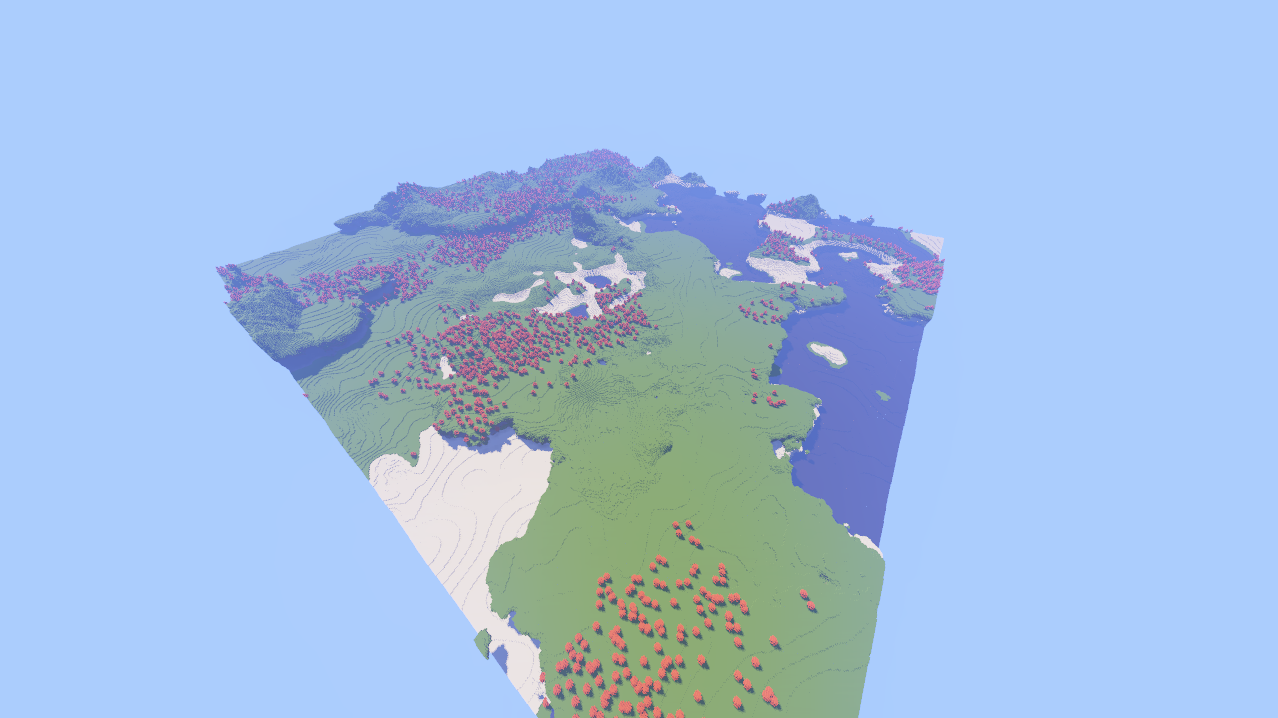
Sparse Lod Octree System
Hybrid Chunk Scaling
The world is divided into chunks, but unlike standard voxel engines where a chunk is always a fixed 32x32x32 volume, my chunks are elastic containers. They maintain a fixed world-space dimension (CHUNK_SIZE) but the internal voxel resolution changes based on a Level of Detail (LOD) index. This means distant chunks can store less data without visibly affecting quality.
This is achieved through a subsampling metric where the storage requirements decrease cubically with distance. A chunk at LOD 0 stores raw voxel data. A chunk at LOD 1 stores data at 1/2 resolution (1/8th memory), and so on.
// Dynamic internal resolution mapping
uint8_t get_voxel_material(const glm::u8vec3& voxel)
{
if (lod_level == 0) {
// Direct mapping for high-fidelity foreground
uint32_t index = voxel.z * 128 * 128 + voxel.y * 128 + voxel.x;
return lod_voxels[index].material;
} else {
// Subsampling for background LODs
uint16_t lod_x = voxel.x / sample_rate;
uint16_t lod_y = voxel.y / sample_rate;
uint16_t lod_z = voxel.z / sample_rate;
// Flattened index calculation for sparse storage
uint32_t index = lod_z * lod_size * lod_size + lod_y * lod_size + lod_x;
return lod_voxels[index].material;
}
}
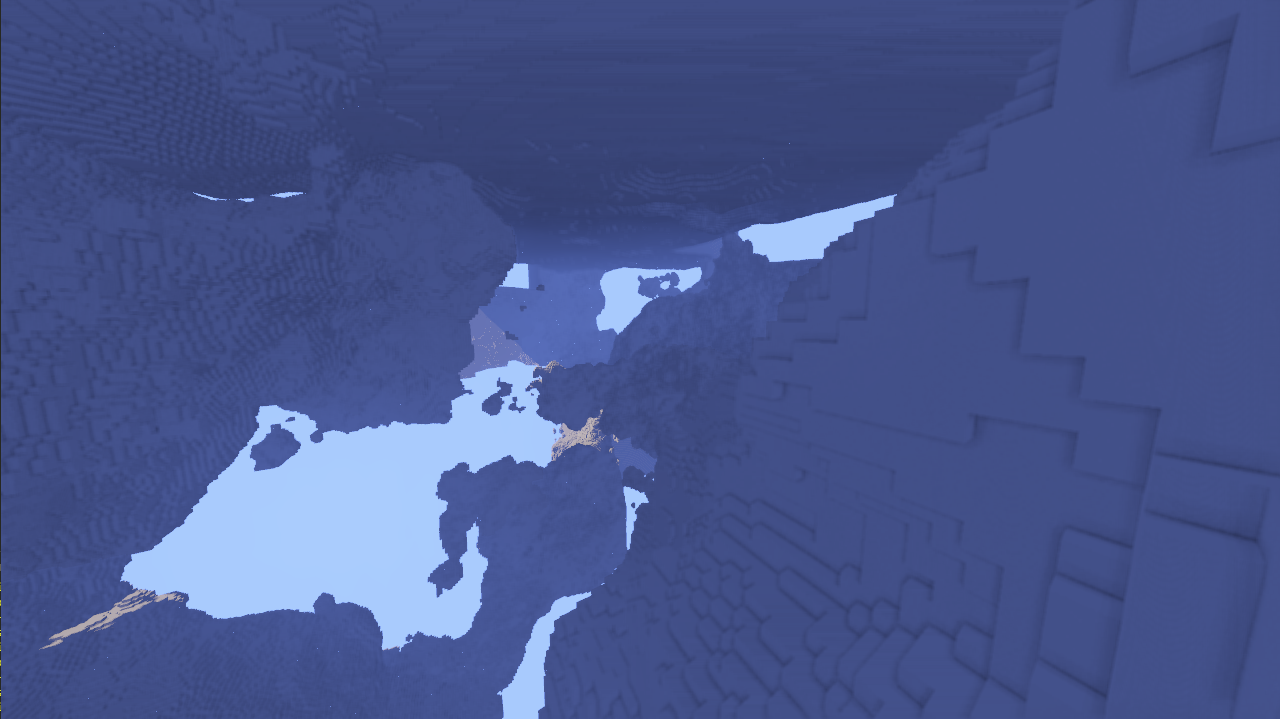


Distance-Based Cascades
The engine calculates the Look-Up Table (LUT) for LOD selection every frame based on the Chebyshev distance from the camera to the chunk center. This creates concentric "shells" of detail radiating from the player, similar to shadow map cascades.
This approach allows us to have perceptibly an infinite render distance whilst keeping resource requirements manageable. Below you will find my attempts of getting the LOD to work, but it is proving to be very difficult to integrate with the Spare Octree!



Asynchronous Terrain Generation
Three-Stage Pipeline
One of the biggest challenges in infinite world generation is preventing frame rate hitches when the player moves into new areas. To solve this, I implemented a three-stage threaded pipeline for chunk generation. The World class manages a pool of worker threads that pull jobs from priority queues, so terrain generation never blocks the main render loop.
- Population Pass 1 (Base Terrain): This stage generates the foundational geology using FastNoiseSIMD. It computes high-frequency mountain ranges, low-frequency rolling hills, and plateau blending. This pass is purely mathematical and thread-safe.
- Population Pass 2 (Decoration): Once the base terrain is solidified, a second pass applies surface features. This includes recursive tree generation, water table leveling, and sand distribution. This pass can cross chunk boundaries by locking neighboring regions to prevent race conditions.
- Greedy Meshing: The final stage converts the volumetric data into renderable geometry.
// Thread orchestration in World::update()
while(true) {
// Priority 1: Base Terrain
chunk = get_population_pass_1_chunk();
if(chunk) {
threads[i] = std::thread(&World::population_pass_1, this, chunk, i);
continue;
}
// Priority 2: Decoration
chunk = get_population_pass_2_chunk();
if(chunk) {
threads[i] = std::thread(&World::population_pass_2, this, chunk, i);
continue;
}
// Priority 3: Geometry Generation
chunk = get_unmeshed_chunk();
if(chunk) {
threads[i] = std::thread(&World::mesh_chunk, this, chunk, i);
}
}Greedy Meshing Optimization
The meshing algorithm solves the "voxel explosion" problem (where 1000 voxels would naively generate 12000 triangles) by implementing greedy surface merging. The algorithm scans each axis-aligned slice of the chunk, identifying runs of identical material faces and combining them into the largest possible rectangular quads.
This reduces the vertex count by an order of magnitude for typical terrain scenarios (i.e. Minecraft-like worlds), which significantly lowers memory bandwidth pressures on the CPU.
Deferred Rendering & Visuals
G-Buffer Architecture
For the visual style I wanted, I needed a deferred rendering path. Instead of calculating lighting during the geometry draw calls (forward rendering), the engine first writes all surface properties to a Geometry Buffer (G-Buffer), then does lighting as a post-process. This makes complex lighting effects like SSAO much easier to implement.
| Attachment ID | Components | Data Precision | Purpose |
|---|---|---|---|
| 0 | RGB + A | RGBA32F | World Space Position + Alpha Mask |
| 1 | RGB + A | RGBA16F | Encoded Normal Vector |
| 2 | RGB + A | RGBA8_UNORM | Albedo (Base Color) |
| 3 | R | R8_UNORM | Specular / Roughness Factor |
SSAO and Lighting
Depth perception in voxel worlds is critical as surfaces would appear very flat and it would be hard to distinguish faces in the same lighting directon. Voxceleron2 implements Screen Space Ambient Occlusion (SSAO) to simulate local shadowing in crevices and voxel corners. The implementation then rotates a small set of sample directions so they follow the surface’s orientation, then uses them to randomly sample the depth buffer giving us an occlusion factor.
// Stochastic depth sampling in Fragment Shader
for(int i = 0; i < SSAO_KERNEL_SIZE; ++i)
{
// Rotate kernel by random noise vector
vec3 sample_position = tbn * uniforms.samples[i].xyz;
sample_position = position + sample_position * SSAO_RADIUS;
// Project back to screen space to read depth
vec4 offset = vec4(sample_position, 1.f);
offset = uniforms.projection * offset;
offset.xyz /= offset.w; // Perspective divide
// Accumulate occlusion based on depth delta
float range_check = smoothstep(0.f, 1.f, SSAO_RADIUS / abs(position.z - sample_depth));
occlusion += (sample_depth >= sample_position.z ? 1.f : 0.f) * range_check;
}Post-Processing Chain
The final visual polish is applied via a composition pass that integrates the lighting buffers with post-processing effects. A separable Gaussian blur is applied to the Bloom buffer, allowing emissive voxels (like lava or lamps) to bleed light into neighboring pixels.